The increasing demand for virtual reality applications has highlighted the significance of crafting immersive 3D assets. We present a text-to-3D 360$^{\circ}$ scene generation pipeline that facilitates the creation of comprehensive 360$^{\circ}$ scenes for in-the-wild environments in a matter of minutes. Our approach utilizes the generative power of a 2D diffusion model and prompt self-refinement to create a high-quality and globally coherent panoramic image. This image acts as a preliminary "flat" (2D) scene representation. Subsequently, it is lifted into 3D Gaussians, employing splatting techniques to enable real-time exploration. To produce consistent 3D geometry, our pipeline constructs a spatially coherent structure by aligning the 2D monocular depth into a globally optimized point cloud. This point cloud serves as the initial state for the centroids of 3D Gaussians. In order to address invisible issues inherent in single-view inputs, we impose semantic and geometric constraints on both synthesized and input camera views as regularizations. These guide the optimization of Gaussians, aiding in the reconstruction of unseen regions. In summary, our method offers a globally consistent 3D scene within a 360$^{\circ}$ perspective, providing an enhanced immersive experience over existing techniques.
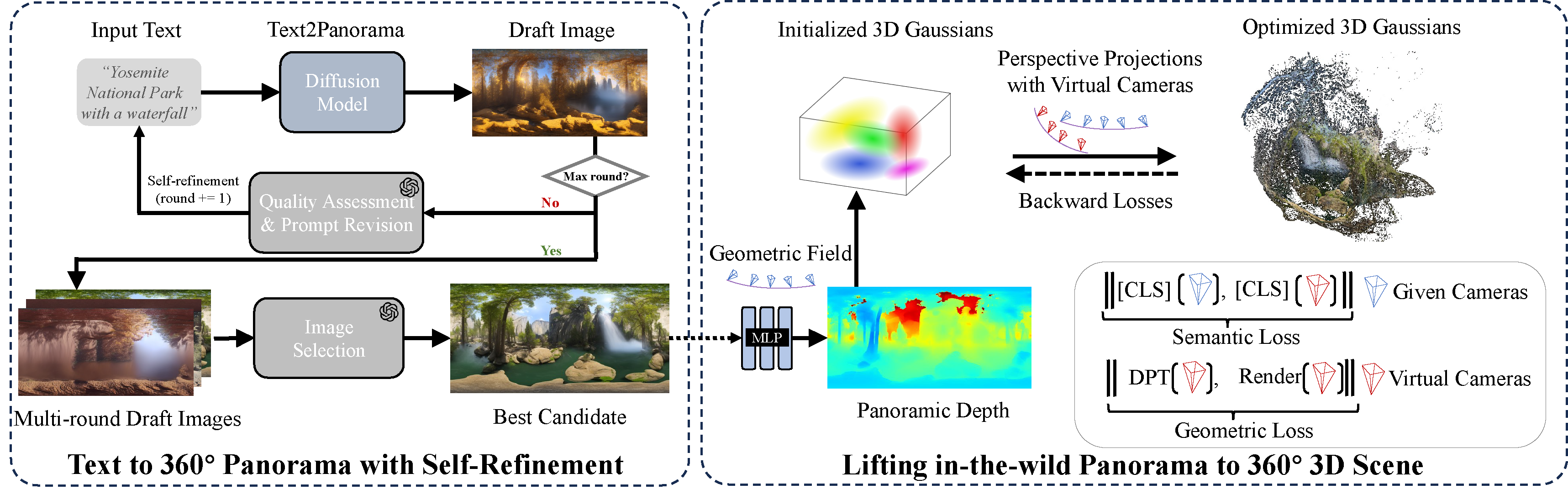
Beginning with a concise text prompt, we employ a diffusion model to generate a 360$^\circ$ panoramic image.
A self-refinement process is employed to produce the optimal 2D candidate panorama. Subsequently,
a 3D geometric field is utilized to initialize the Panoramic 3D Gaussians. Throughout this process,
both semantic and geometric correspondences are employed as guiding principles for the optimization of the Gaussians,
aiming to address and fill the gaps resulting from the single-view input.
Unlike previous works that generate 3D scenes through a time-consuming score distillation process or progressive inpainting, our work uses Panoramic Gaussian Splatting to achieve ultra-fast “one-click” 3D scene generation. We integrate GPT-4V to facilitate iterative user input refinement and quality evaluation during the generation process, a feature that was challenging to implement in previous methods due to the absence of global 2D image representations.
In each row, from left to right, displays novel views as the camera undergoes clockwise rotation in yaw,
accompanied by slight random rotations in pitch and random translations.
LucidDreamer hallucinates novel views from a conditioned image (indicated by a red bounding box) but lacks global semantic,
stylized, and geometric consistency. In contract, our method provides complete 360$^\circ$ coverage without any blind spots
(black areas in baseline results), and show globally consistent semantics.


Our generated 3D scenes are diverse in style, consistent in geometry, and highly matched with the simple text inputs.














@inproceedings{zhou2024dreamscene360,
title={Dreamscene360: Unconstrained text-to-3d scene generation with panoramic gaussian splatting},
author={Zhou, Shijie and Fan, Zhiwen and Xu, Dejia and Chang, Haoran and Chari, Pradyumna and Bharadwaj, Tejas and You, Suya and Wang, Zhangyang and Kadambi, Achuta},
booktitle={European Conference on Computer Vision},
pages={324--342},
year={2024},
organization={Springer}
}